The object of this assignment is to gain some familiarity with nltk (which you installed a few weeks ago) for manipulating textual data, and scikit-learn; plus some of the methods we've discussed in lecture (naive Bayes classifier, principle component analysis -- note that the slides from lecture 6 are available via the Piazza resource page for the course).
Chpt 2 of the nltk book
contains various instructions for accessing the nltk data you installed,
including a sample from the gutenberg corpus. For example:
from nltk.corpus import gutenberg
will list the eighteen sample files together with their word counts.
The word counts of the three Shakespeare plays included
(caesar, hamlet, macbeth) are 25833+37360+23140 for a total of 86333 words.
for file in gutenberg.fileids():
print file,len(gutenberg.words(file))
I. The object of the first part of this assignment is to experiment with the
author attribution methodology discussed in lecture. As was discussed there,
it is reasonable to take the above text in 5000 word blocks (say seventeen of them), and
compare the stopwords in those blocks to a roughly comparable amount of text
from some other author. For example, you
could consider the file austen-persuasion.txt (98171 words) or
milton-paradise.txt (96825 words), or you could use roughly 90000 words from
melville-moby_dick.txt (from a total of 260819).
[In addition, the Gutenberg site has over 42,000 free ebooks (including, e.g., all of the ones written by Baum, plus the 15th "The Royal Book of Oz", but not the later ones by Thompson)]
So the first part of the assignment is to take the roughly thirty-six 5000 word blocks from two authors, find the 50 most frequent words in this combined corpus, and see whether principle component analysis to distinguishes the authors and finds the most discriminating words. For this you can either use standard software in nltk for parsing and manipulation text, or write your own simple programs, or use scikit learn or other standard software for additional analysis, or again write your own simple program.
It might be fun to consider more than two authors and see whether the different authors all form their own clusters (k-means, to be covered in class, might work for this). To distinguish them might require more than just the first two principle components. This part of the assignment is relatively open-ended. There are various samples of data to analyze and visualize, and I'm hoping to have various demos of what you chose when we next meet on 29 Mar.
To make this easier, I've posted a notebook containing a method for doing part of it (using the FreqDist method described in chpt 2 of the nltk book). Feel free to use code from that notebook or improve on it.
|
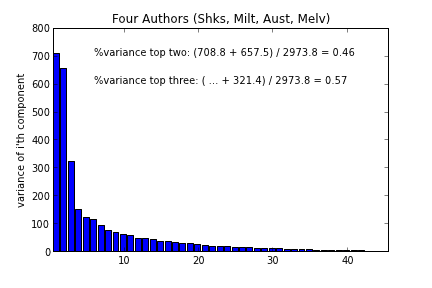
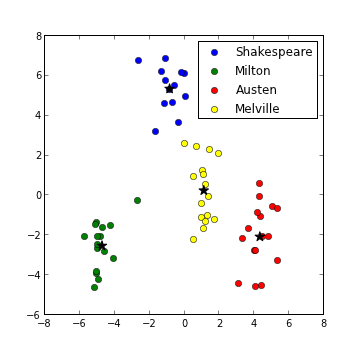
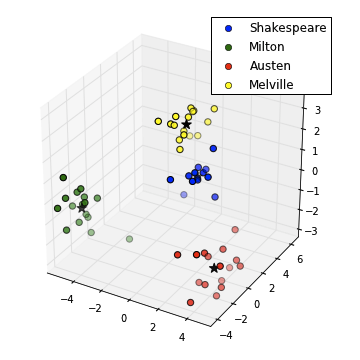
| I did have a quick look at a four author case, using Shakespeare/Milton/Austen/Melville texts (16th,17th,18th,19th century, resp.) texts from nltk-data.gutenberg.corpora, where (not surprisingly) a third principle component played a role (see variances at left). A potential ambiguity between Shakespeare and Melville in the first two dimensions (below left) is entirely lifted by the 3rd dimension (same data, below right -- note 3 dimensions is still much smaller than the original 50 stopwords). Again the k-means classifier works well (with k=4, means given by black stars in plots below). |
The nltk data also has some classified movie review data, collected
locally.
It can be accessed by
from nltk.corpus import movie_reviews
and has 2000 reviews
print len(movie_reviews.fileids())
2000
with a mean length of under 800 words
mean([len(movie_reviews.words(file)) for file in movie_reviews.fileids()])
792
and 1000 of each type, positive and negative:
negids = movie_reviews.fileids('neg')
posids = movie_reviews.fileids('pos')
print len(negids),len(posids)
1000,1000
One fun experiment is to use 1900 of them as the training set for a classifier, and the rest as the test set. This would give 100 test instances to assess the reliability of the classifier. As above, you have the choice of writing your own simple naive bayes classifier, along the lines discussed in class, or using the NaiveBayesClassifier from nltk.
There is also the question of what features to use. One possible methodology would be to eliminate words smaller than 2 characters and use lowercase for the rest. (A post employing this methodology for twitter data is here, using nltk tools.) Which turn out to be the most important features (i.e., the most discriminating words for the positive/negative test)? Other features to consider are bigram collocations -- I strongly suspect that bigrams will be even more accurate discriminators.
Finally, devise some experiment using available on-line data. Ordinarily you would want to use data similar to the test set, in this case movie reviews, so that might be a possibility. (You could ingest a sample of recent movie reviews, say about ten, and assess by eye whether positive or negative. Or you could take a larger sample and compare statistically against Rotten Tomatoes.) But the trained model might also turn out to be more broadly applicable, say to the book data, or to book reviews, or to blog postings, or twitter data. (The difficulty in this part of this exercise is to find some way to assess the reliability of the classifier.)
Note: I belatedly noticed that parts of this example are given in nltk chpt 6 (examples 6.4, 6.5), and you're welcome to use some of that code. The exercise will be expanded slightly to contrast some differences from that approach, in particular using a different set of features.
Here is a notebook containing a method for doing part of it. I'll post some follow-up hints and examples after class Fri, with more pointers to available on-line resources.